
|
|
PfEFFER ConceptsHydraulic Flow |
Homogeneous reservoirs are the exception, rather than the rule. Most reservoirs are heterogeneous and can be subdivided into layers that are internally homogeneous (from an operational standpoint), but are distinct from adjacent layers. Reservoir characterization is a cooperative project that is shared by the petroleum geologist and the reservoir engineer. The criteria for subdivision used by the geologist are those of facies recognition that identify rocks in terms of genesis. In many cases, the genetic units defined by the geologist are useful operational units for the engineer in reservoir work because the unit boundaries commonly coincide with distinctive changes in hydraulic behavior. However, this coincidence is not always the case and if the purpose of the reservoir subdivision is for engineering, then it is best to focus on the critical hydraulic properties.
This geology/engineering distinction has been recognized since the 80's when the hydraulic flow unit concept was introduced. The flow unit is defined as a reservoir zone with lateral continuity, whose geological properties that control fluid flow are internally consistent and different from adjacent flow units. The controls on fluid flow are ultimately the pore-throat size, so that the flow unit is a zone with relatively uniform dominant pore throat radius, resulting in a consistent flow behavior. Flow units can be recognized most completely from capillary pressure curves measured from core samples. They can also be defined quite well from the recognition of distinctive clusters of r35 dominant pore throat radius estimations from core porosity and permeability measurements, or their approximations by the permeability/porosity ratio in non-granular rocks.
Within the water-free reservoir unit itself, subdivision between flow units will also be seen in abrupt changes in (irreducible) water saturation that reflect matching changes in pore throat size. Notice that adjacent flow units are in hydraulic communication, but that their distinction is important because they show the most and least productive zones in primary recovery and their lateral and vertical geometry also affects sweep efficiency in secondary operations. As such, the flow unit is distinct from a compartment that is not hydraulically connected to other compartments, So, the flow units within a compartment will be subject to a common Free Water Level, but the separate compartments will have different FWLs as shown by pressure analysis from drill-stem tests (DSTs) of repeat formation tests (RFTs).
Access to capillary pressure measurements and other pore and pore-throat data is the rare exception, rather than the rule, so that flow unit subdivision is usually made on the basis of wireline logs (and core measurements where available). The choice of logs should be dictated those properties that control hydraulic flow in the reservoir under consideration. Shale content as given by the gamma-ray or other shale-sensitive log(s) is often an important control in clastic reservoirs, but may be less important in carbonate reservoirs where sometimes the distinction between limestone and dolomite units made by the photoelectric factor could be a key discriminator. The subdivision of flow units will be a multivariate problem when the process requires several logs and a popular method for this task is that of cluster analysis.
Cluster analysis is the name given to a wide variety of mathematical techniques designed for classification. The techniques all have a common goal—to group objects that are similar and to distinguish them from other dissimilar objects on the basis of their measured characteristics. On the basis of everyday experience it should be obvious that individual objects can be grouped or distinguished in different ways according to various criteria we may choose to apply. Since it is the purpose of the FLOW classification in PfEFFER to zone the reservoir into consistent flow units, log variables and log transforms should be chosen that are significantly related to hydraulic properties, either explicitly (such as porosity) or implicitly (such as lithology changes that are associated with changes in pore type). In some types of reservoir, the link may not be so obvious, thus the choice of logs will be more serendipitous. In this event, the results should be evaluated by interpretation or reference to external information or criteria.
The most common class of clustering methods used in geology and other sciences is that of hierarchical analysis (Romesburg, 1984). First, a database of attribute measurements is compiled for the objects to be clustered. Then a matrix of similarities or statistical distances between the objects is computed on the basis of the collective treatment of the attributes. The clustering algorithm is applied to the similarity matrix as an iterative process. The pairs of objects with the highest similarities are merged, the matrix is recomputed, and the procedure repeats. Ultimately all the objects will be linked together as a hierarchy, which is most commonly shown as a dendrogram. At this point, the objects are in one giant cluster. Some decision must now be made concerning where to cut the tree diagram into branches that coincide with distinctive groupings. The choice may be based either on visual inspection, a mathematical criterion that appears to reveal a natural breaking point, or (preferably) some measure that can be used to check potential clusters against some external standard.
In many applications of cluster analysis there are no relationships between objects other than the similarities implied by their attributes. Zones from logs have an additional property: they are ordered along the dimension of depth. This constraint can be used to limit the analysis to the consideration of stratigraphically neighboring units, thus only vertically adjacent zones and clusters may be merged into larger clusters. The method is extremely efficient in computer usage. It is an adaptation of a conventional agglomerative and hierarchical cluster analysis, but has the additional adjacency constraint. The procedure also incorporates the algorithm of incremental sums of squares introduced by Ward (1963). Clusters are defined so that the sum of the variances within the clusters is the minimum possible. By using Ward's method and the adjacency constraint, the succession of zones is replaced by a stratified sequence of partitions that merge into coarser units at higher ranks. The methodology is illustrated by the exceedingly simplified flow-diagram of Figure 28 .
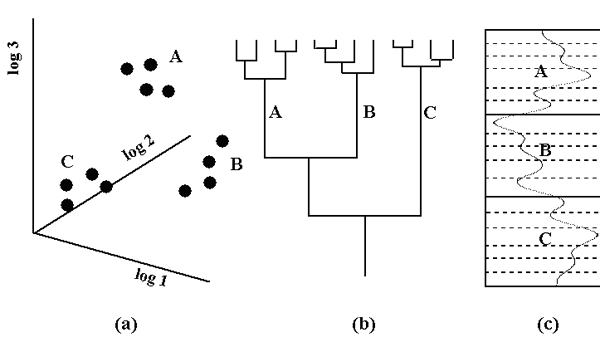 |
| Figure 28: Stages of cluster analysis of log data: (a) multivariate database of zones ; (b) dendrogram of zones according to hierarchical clustering of the zones based on their similarities; (c) classification of zones related to input logs and plotted in order of depth. |
This depth-constrained variation on clustering was introduced by Grimm (1987),
who wrote a computer program for stratigraphic zonation of palynological data.
An interesting case-study application of the technique is to stratigraphic
zonation of logging data is also described by Gill et al. (1993) who compared
the results of stratigraphic subdivision with those of conventional lithostratigraphy
drawn from drill cuttings. Notice also that if only one log variable is used
as the basis for clustering, then the method becomes a log blocking technique.
By the same token, depth-constrained cluster analysis is equivalent to the
operation of multivariate blocking.