We assign an initialization probability pk for each element k. Each
probability pk is simply the relative frequency of occurrence of element k
as observed in the field. Note that 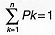 where n is the total number of element types in the model. In the future work,
we will iteratively adjust these probabilities pk to conform the output model
to the observed data (see the final section for details).
where n is the total number of element types in the model. In the future work,
we will iteratively adjust these probabilities pk to conform the output model
to the observed data (see the final section for details).
Once the probabilities are calculated, a lattice node (i, j) is chosen at
random. If the node is already filled with an element, we choose another
(on the computer, this takes very little time, on average). If the node is
empty we fill it with an element as follows: Generate a random number x
between 0 and 1 (0 < x < 1). Partition the interval from 0 to 1 into n
subintervals, where the mth subinterval has width pm. The starting point of
each subinterval m is xm-1 and the ending point is xm, where
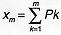 (and x0=0). The relationship
between the probabilities pm and the intervals [xm-1, xm] is illustrated
below:
(and x0=0). The relationship
between the probabilities pm and the intervals [xm-1, xm] is illustrated
below:
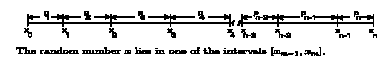
Node (i, j) is filled with element m where m is such that xm-1 < x < xm. We continue filling the lattice unit 20% of the lattice nodes are filled. The model is now initialized and ready for the model generation phase.
Previous Page--Methods ||
Next Page--Generation of the output model
Dakota Home ||
Start of the Stochastic Modeling Report