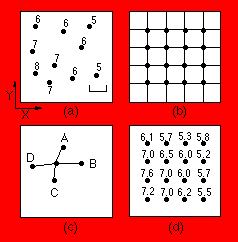
The figure above shows a series of observations; each point is characterized by its X coordinate (east-west or across the page), its Y coordinate (north-south or down the page), and its Z coordinateŃthe value to be mapped. On the illustration, values of Z are noted beside each point. The observations may be identified by numbering them sequentially as they are read by the program, from 1 to i. Therefore, an original data point i has coordinates X(i) in the east-west direction, Y(i) in the north-south direction, and value Z(i). In (b), a regular grid of nodes has been superimposed on the map. These grid nodes also are numbered sequentially from 1 to k. Grid node k has coordinates X(k) and Y(k) and has an estimated elevation Z(k). To estimate the grid node value Z(k) from the nearest n data points, these points must be found and the distances between them and the node calculated. The search procedure may be simple or elaborate. Assume that by some method the n data points nearest to grid node k have been located. The distance D(k) from observation i to grid node k is found by the Pythagorean equation
Having found the distances D(ik) to the nearest data points, the grid point elevation Z is estimated from these. The completed grid with all values of Z is shown in (d).
This type of algorithm is sometimes called a "moving average," because each node in the grid is estimated as the average of values at control points within a neighborhood that is "moved" from grid node to grid node. In effect, values at the control points are projected horizontally to the location of the grid node, where they are weighted and averaged.
On to linear projection gridding...
