 |
|
Kansas Geological Survey Open-file Report 2003-30 |
Lithofacies Prediction: Tools, Methods, Results
Steps to Predict Lithofacies
In Non-cored Wells
-
Determine predictor variables, lithofacies categories, and optimal predictor tool in an iterative, logic-based, trial and error process.
-
Optimize neural network parameters through cross-validation and logic-based trial and error.
-
Select two neural network models, one for wells with PE curve and one for wells without PE curve.
-
Develop code to automate process of generating the Marine-Non Marine curves and neural network predictions.
-
Generate predicted lithofacies and probability curves and output LAS format files through batch processing of input LAS files.
 |
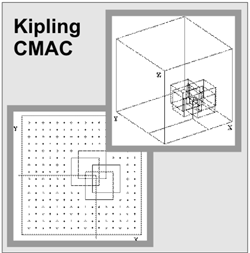
Kipling/CMAC tesselation of predictor variable (well log) space in two and three dimensions. This non-parametric classification technique was considered but not used in favor of the neural net. |
Automation
Significant custom programming by Bohling has made possible the generation of the Marine-Nonmarine predictor variable LAS curve through a Visual Basic routine in MS Access that allowed the mining of the KGS Oracle data base, automated cross-validation exercises via R-language scripts, and batch prediction of lithofacies from a large LAS file data base by extending Kipling.xla with Visual Basic Code that applied the neural network and output an LAS lithofacies curve files for each well in the data set.
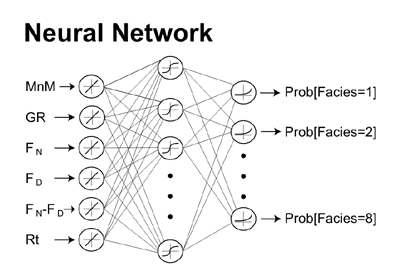 |
Predicted lithofacies probabilities from logs and marine/non-marine indicator (MnM). PE curve, not shown, was used when available. A standard single hidden-layer neural network was used (Duda et al., 2001) and we focused our model calibration efforts on the selection of an appropriate number of hidden-layer nodes, which governs the richness of the model, and an appropriate damping parameter, which constrains the magnitude of the network weights to help prevent overtraining. |
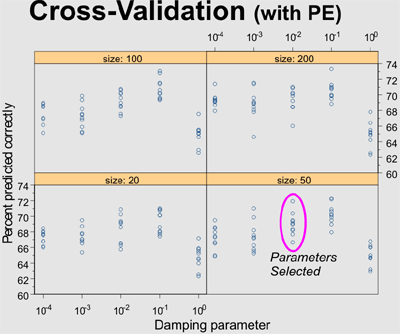 |
Results for model with GR, Nphi, Dphi, Nphi-Dphi, Rt, PE, and Marine-nonMarine indicator as predictor variables. Ten data points are shown for each combination of network size (number of hidden-layer nodes) and damping parameter, each point representing a different random split of the keystone data into training (2/3) and prediction (1/3) subsets. Parameters selected for PE model were 50 hidden-layer nodes and 0.01 damping parameter. 100 and 0.01 were selected for the no PE model. |
|
|
|
e-mail : webadmin@kgs.ku.edu
Last updated May 2003
http://www.kgs.ku.edu/PRS/publication/2003/ofr2003-30/P2-05.html