SKUNK WORKS INTERNATIONAL
(David, L., Swaney, D., Camacho, V)
Objective: Make use of the existing budgets to force the clustering of the coastal cells in the LOICZ database.
Methodology:
The overall approach is similar to performing supervised classification on remotely sensed image.
1] First a Principal Component Analysis (PCA) is performed on the variables of interest. . In essence this approach allows for natural groupings of behavior to be derived from the scatterplot of the variables. In the case of a remotely sensed image the variables are the multiple bands available, in the case of the budgets the choice was narrowed down to DDIP and DDIN. The natural groupings (called ROI’s in remote sensing) are then used as training sites for the whole collection of coastal cells in the LOICZ database.
2] The ROI’s could initially have one or more budget points. In the cases where they had more than one it was decide to only take a single point to represent that particular ROI and use the remaining points to later calibrate and/or verify the typology results. The way the representative budget points were chosen was primarily geographic. In essence since the primary author of this exercise has a better feel for the Asian-Australian budgets, preference was made to make use of these sites.
3] Unfortunately, since the budget point locations do not exactly match up with the coastal typology cells there was a need to first locate the nearest neighbor to each budget point and have those typology points represent the ROI’s.
4] The newly added SUPERVISED CLASSIFICATION tool in the LoiczView was then used to typologize all the LOICZ coastal cells.
Summary of Results:
1] PCA of budgets
|
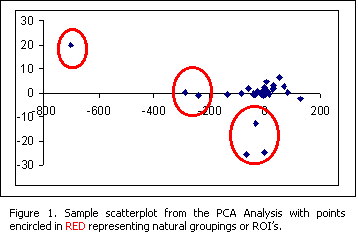
The following observations related to the PCA Analysis were noted:
· The PCA was applied to the whole budget data set. Including both the seasonal and annual data. A total of 202 points.
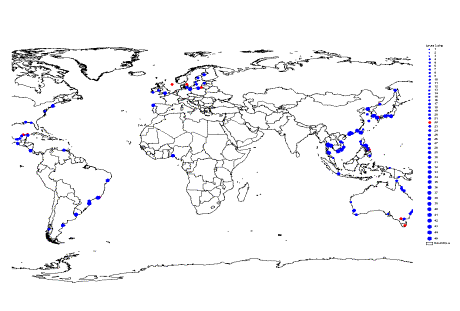
· The first ROI identified was point 17 shown in the upper left corner of figure 1, an obvious outlier in the whole distribution. It was later identified to represent Manila Bay, Philippines.
· The next 13 ROI identified were later identified to be consist of budgets from the Asian region.
· A total of 45 ROI’s were identified for whole budget database.
· It was noted that the DDIN distribution was the dominant variable in teasing out the ROI’s from the scatterplot.
2] Picking the representative budget point
|
|
· When more than one budget site comprise a particular ROI, only one budget was chosen to be a representative site. In the example above (Fig. 2) ROI 22 is highlighted in RED. In this case the budget from the Philippines was chosen to represent the ROI
· When there are seasonal budgets available and the seasonal budgets did not end up belonging to the same ROI, the initial approach is to look for budget points that have only one season or an annual budget for simplification.
· There are budget points however where seasonality, it seemed, should be taken into consideration. For example a data point (call it A, located in Asia) belonged to ROI 16 in one season and then to ROI 22 for another season. Another data point therefor (this time located outside Asia) was considered to represent ROI 16. However this second data point (point B) also had two seasons and it was discovered that the second season likewise belonged to ROI 22. ROI 16 and ROI 22 were therefore collapsed as ROI 16 representing systems where season matters.
· Applying similar analysis the number of ROI’s were reduced from 45 to 40.
· It is recommended that future approaches for simplification might instead make only annual budgets. However, it would even be better if all the budgets were calculated seasonally and the approach applied to that data set in order to be able to tease out the seasonality of the biogeochemical budgets.
3] Matching ROI representative points and the coastal typology cells.
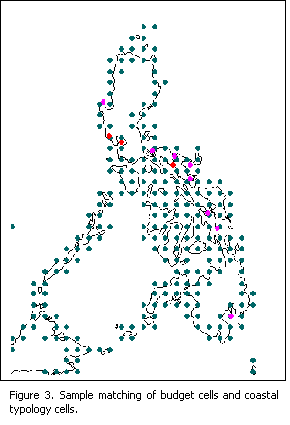
· Matching was done using nearest neighbor.
4] Supervised Classification
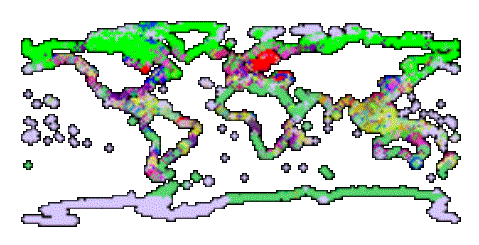
· Three trials were done using all 40 ROI’s and several choices of LOICZ database points
· 1st Trial for supervised Class (allclust.html)
· All Variables
· 40 Clusters and 2 Standard Deviations
· Only 1% of the total dataset was not classified
|
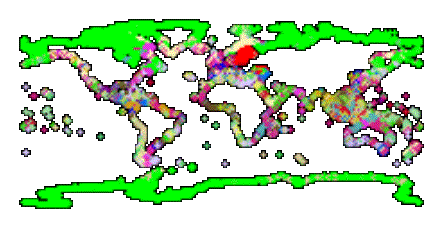
· 2nd Trial for supervised Class (allclust2.html)
· Choice of the data set made use of the results of the multiple regression analysis of all the variables in the LOICZ database. Since it became apparent with the PCA analysis that the differences between the ROI’s were being influenced more by the DDIN, it was decided to make use of all the data that had a high correlation with this variable.
· The following variables will be used in calculations on this data set:
|
· 40 Clusters and 2 Std. Dev
· less than 1% not classified
|
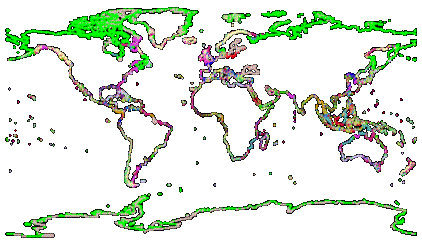
· 3rd Trial for supervised Class (allclust3.html)
· Variables same as 2nd trial
· 40 Clusters and 1 Std. Dev.
· Only 17% not classified
|
Additional Work
The model results are to be compared with the remaining unused points in each ROI.
Eventually, it is the goal to be able to compute DDIN and DDIP from the coastal cells. However, two things are necessary before this can be implemented.
(1) A good proxy for DDIN needs to be determined from the available LOICZ data set. (DENNIS)
(2) There must be a way to calculate the estuary area in each cell. (VICTOR)