DESCRIPTION OF DATABASE VARIABLES
The variables used are presented in one of three forms:
Continuous: The values represent measurements, estimates or calculations of the actual environmental parameters.
Scaled Classes (pseduo-continuous): The values are derived from classified data sets, but have been adjusted so that the number used to identify each class is roughly proportional to the values in that class. Variables of this type include wave height, tide range, and soil carbon.
Example: The original source of the tide range data listed classes 1-5, corresponding to range values of tideless, <2 m, 2-4 m, 4-8 m, and >8 m. We have renumbered the classes to 0, 1, 3, 6, and 10 to produce an approximate correspondence between label and magnitude.
Classed (or discrete) data: The data are arranged into numbered groups that form a logical numerical progression reflecting the trend in values, but there is no effort to achieve any proportionality between the index number and the group value.
Example: Soil texture classes are numbered 1-5, with 1 being the finest and 5 the coarsest. The order of grain sizes is 5>4>3>2>1, but the numbers bear no particular relation to mean diameter, sieve size, % clay, or any of the other quantitative measures of texture.
Types of variables, and implications for analysis:
With one class of major exceptions (river basins, discussed below), the data presented represent conditions within the 30' lat-long grid cell with which they are associated. In addition to the classed-continuous distinction, variables may be intensive or extensive, normalized or absolute, and primary or derived (e.g., statistical). These categories are important for some comparisons involving typologic clustering, and are especially important if data are downloaded and combined or manipulated off-line.
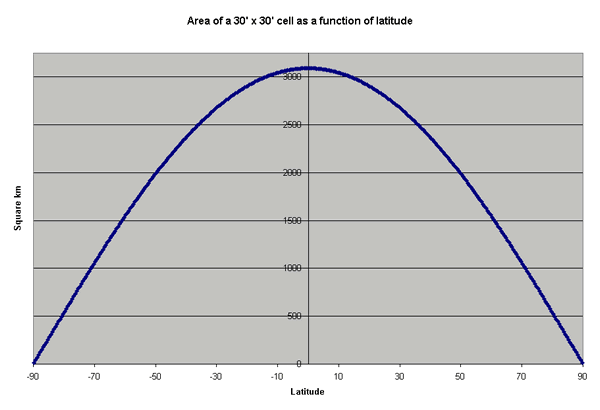
Because the length of a degree of longitude varies as a function of latitude, the same inventory of material per unit area (km-2) would yield a lower total amount per cell at high latitudes than at the equator (see figure below).
Example: Population is an extensive variable, while population density is intensive (independent of spatial extent). In comparing human impacts between high and low latitudes, it would be safer to use population density (which is normalized, and thereby becomes intensive) as a classifier than population.
Guidelines: If the units of a variable are length (e.g., mm of precipitation), or if it is a concentration, a density, or any other ratio (e.g., wind speed), it is an intensive variable and can be compared across units of different area. If the units are volume, mass, or raw number (e.g., islands, populations) the comparison can be expected to be area-sensitive. When cell variable values are combined (for example, in an off-line calculation), intensive variables would normally be averaged, extensive variables would be summed -- although in the case of intensive variables, weighted averaging may be appropriate if the cells differ substantially in area.
The exceptions to the single-cell reference mentioned above are the drainage basin variables supplied by UNH-BAHC.
These variables are listed in red type and are in a separate category on the data selection page in order to distinguish them from the rest of the variables. For the drainage basins, the values presented are for the entire river basin that discharges through the indicated coastal cell. This is done in order to examine the focused effect of land masses on the limited portions of the coastal zone directly affected by river discharge. These effects are important to coastal processes, but the user is cautioned that the magnitudes of values and the nature of some of the variables can be very different from the cell-specific data sets, and care must be exercised in any sort of combined analysis. The potential for confusion is greatest when normalized variables are available for both the local cells and the basins assigned to specific cells. Land cover, expressed as a percent of the total area occupied by a given ecosystem or activity, will have similar numerical values at the cell and basin levels -- but a given percentage of land cover in the Amazon basin is a very different feature than the same percentage within a 30' coastal cell. For more detailed discussion and cautions, see the explanatory page linked above.