
Clustering involves grouping data points together according to some measure of similarity. One goal of clustering is to extract trends and information from raw data sets. An alternative goal is to develop a compact representation of a data set by creating a set of models that represent it. The former is generally the goal in geographic information systems, the latter generally the goal of pattern recognition systems. Both fields use similar, or identical techniques for clustering data sets.
There are two general types of clustering that are used on geographic data: supervised and unsupervised clustering. Supervised clustering uses a set of example data to classify the rest of the data set. For example, consider a set of colored balls (all colors) that you want to classify into three groups: red, green, and blue. A logical way to do this is to pick out one example of each class--a red ball, a green ball, and a blue ball--and set them each next to a bucket. Then go through the remaining balls, compare each ball to the three examples and put each ball in the bucket whose example it matches the best.
This example of supervised clustering is illustrative because there are two potential problems. First, the result you get is going to be dependent upon the balls you select as examples. If you were to select a red, an orange, and a blue ball, then it might be difficult to classify a green ball. Second, unless you are careful about selecting examples, you may select examples that don't represent the distribution of data. For example, you might select red, green, and blue balls, only to discover that most of the colored balls were cyan, purple, and magenta (which are in between the other 3 primary colors). This shows the importance of selecting representative samples when you execute supervised clustering.
Unsupervised clustering, on the other hand, tries to discover the natural groupings inside a data set without any input from a trainer. The main input a typical unsupervised clustering algorithm takes is the number of classes it should find. In the colored balls case, this would be like dumping them into an automatic sorting machine and telling it to create three piles. The goal of unsupervised clustering is to create three piles where the balls within each pile are very similar, but the piles are different from one another.
WLV implements both unsupervised and supervised clustering. The unsupervised clustering algorithm is the k-means algorithm, originally described by MacQueen (1965). It incorporates some modifications to improve its robustness to missing data and poorly behaved data sets.
One of the most important characteristics of any supervised or unsupervised clustering process is how to measure the similarity of two data points. In the case of geographically indexed data, a data point is a geographic location. A single location will generally have multiple variables associated with it. So we can define a similarity measure between two data points based on the values of their variables.
In WLV, the clustering tab lets the user control all of the important parameters for supervised or unsupervised clustering. For supervised clustering, the only relevant parameter is the distance measure, or similarity measure. Typically, the scaled distance measure is the first one to try on geographic data sets.
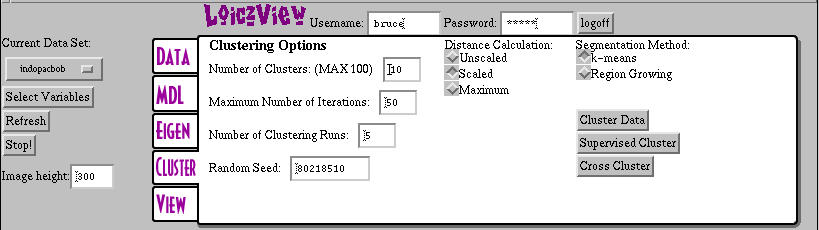
For unsupervised clustering, all of the parameters and checkboxes affect the outcome of the algorithm. The most important box is the Number of Clusters parameter that specifies how many classes the algorithm will create from the data. If you are at a loss as to how many clusters there should be, try using the minimum description length [MDL] tool. Often, the best thing to do is experiment. Start with ten and then go up or down depending upon how you like the results.
The remaining parameters on the left side of the tab control mostly internal aspects of the k-means clustering algorithm. The Maximum Number of Iterations parameter specifies how long the program waits for a single clustering run to finish. If you have a large or complex data set, it is reasonable to make this number larger. There is almost no reason to make it smaller.
The Number of Clustering Runs parameter is kind of like the quality v. speed slider on a color printer dialog window. When you make this number smaller (like 1 or 2), you will get results faster, but they may not be as good. When you really want a high quality result, boost the number to a value from 10-20. Using the value 5 for this parameter seems to be a good tradeoff of speed versus quality.
Finally, the Random Seed parameter controls the random numbers used by the clustering algorithm (which is a stochastic, or randomized process). If you want to duplicate a previous clustering, for example, set the random seed to the previous value. This will guarantee that you get identical results. Most of the time, however, you will not need to change this parameter.