





Dakota Aquifer Program--Geologic Framework
Hodgeman County Study, part 8 of 12
Well clustering by the Ward's method
For any real multivariate sampling it is not possible to prepare
as detailed a tree as the one in Figure 2.
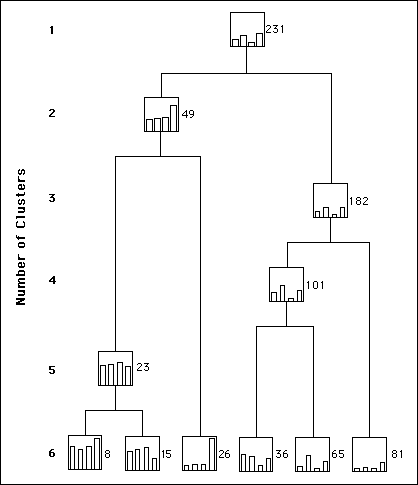
Figure 6 is a possible alternative rendition restricting the attention
to the final stages of the clustering, which customarily are the ones
with the partitions of interest. A bar diagram with the mean value of
the attributes per cluster is one way to reduce the dimensionality of
the data. In Figure 6, the vertical axis goes from 0-150 ft and the
thickness sequence from left to right is upper "J", lower "J", Kiowa,
and Cheyenne cumulative sandstone thickness. The numerical value
denotes the number of wells in the cluster.
Figure 6. Final portion of the Ward's method tree
for the training set of the case study. The horizontal axis does not
have a scale and the boxes are bar diagrams for the coordinates of
the centroids in a vertical scale 0-150 ft.
Naming clusters for easy reference in the text is another challenge
in the display of results. Here we decided to take advantage of the
uniqueness of cluster size and label each cluster by its size.
Remember that Ward's method progresses from largest to smallest
number of clusters. Traveling the tree in inverse direction from its generation one can observe that:
- The topmost bar diagram provides a pictorial representation of the mean value per attribute for the whole sampling whose size is 231 in this case. The last merger is between a group of 49 wells with the rest of the 182 wells. The smaller cluster has the wells with the most sandstone, especially for the Kiowa.
- Cluster 49 results from the merging of clusters 23 and 26 that mostly share large amounts of sandstone for the Cheyenne.
- At the three-cluster level Ward's method merges cluster 81 and 101 that basically share all average values except for the second attribute from the leftčcumulative sandstone thickness for the lower "J".
- The previous four-cluster stage merges clusters 36 and 65, which differ only in the amount of upper "J" sandstone.
- The five-cluster stage merges clusters 8 and 15 whose main discrepancy is the amount of cumulative sandstone in the Cheyenne.
- So far all breaking clusters relate to interesting characteristics on which to base the discriminant analysis in the next step. The six-cluster stage is no exception but the partition contains two clusters that are too small for a regionalized classification, thus bringing to a halt the interest on continuing analyzing the declustering of the tree.
The training set for discriminant analysis should be the partition into five clusters that have the sizes and means given in Table 2.
Table 2. Size, proportion, and means for the partition into five clusters
| Group size | Proportion | Attribute | Mean |
| 23 | 0.10 | Upper "J" cum. ss | 90.4 |
| | | Lower "J" cum. ss | 92.8 |
| | | Kiowa cum. ss | 102.9 |
| | | Cheyenne cum. ss | 83.4 |
| 26 | 0.11 | Upper "J" cum. ss | 22.3 |
| | | Lower "J" cum. ss | 28.1 |
| | | Kiowa cum. ss | 29.0 |
| | | Cheyenne cum. ss | 141.6 |
| 36 | 0.16 | Upper "J" cum. ss | 70.2 |
| | | Lower "J" cum. ss | 65.0 |
| | | Kiowa cum. ss | 23.6 |
| | | Cheyenne cum. ss | 55.0 |
| 65 | 0.28 | Upper "J" cum. ss | 17.6 |
| | | Lower "J" cum. ss | 69.6 |
| | | Kiowa cum. ss | 9.4 |
| | | Cheyenne cum. ss | 43.0 |
| 81 | 0.35 | Upper "J" cum. ss | 12.0 |
| | | Lower "J" cum. ss | 12.3 |
| | | Kiowa cum. ss | 7.5 |
| | | Cheyenne cum. ss | 35.6 |
Previous Page--The Dakota Aquifer Case Study ||
Next Page--Discriminant analysis
Dakota Home ||
Start of Hodgeman County Study
Kansas Geological Survey, Dakota Aquifer Program
Updated Sept. 16, 1996.
Scientific comments to P. Allen Macfarlane
Web comments to webadmin@kgs.ku.edu
The URL for this page is HTTP://www.kgs.ku.edu/Dakota/vol1/geo/hodge8.htm