Hodgeman County Study, part 6 of 12
In regionalized classification the interest is in the calculation
of the probabilities 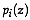 for the
same realizations in the training set already classified by the
prior cluster analysis. Once one has all the probabilities
, reallocation of the sites
to the group with the highest probability is a trivial endeavor.
This reallocation offers an opportunity to check results and compare
methods in case the user wants to consider more than one type of
cluster analysis or discriminant analysis. Results from cluster
and discriminant analysis should be comparable only with minor
variations that one should employ to select methods and
parameters yielding the most consistent results.
for the
same realizations in the training set already classified by the
prior cluster analysis. Once one has all the probabilities
, reallocation of the sites
to the group with the highest probability is a trivial endeavor.
This reallocation offers an opportunity to check results and compare
methods in case the user wants to consider more than one type of
cluster analysis or discriminant analysis. Results from cluster
and discriminant analysis should be comparable only with minor
variations that one should employ to select methods and
parameters yielding the most consistent results.
The final step in regionalized classification is the mapping of groups, which one can accomplish by arbitrarily assigning colors or black and white patterns to the groups. As arbitrary as the color or pattern selection may be, it always helps to select a combination of alternatives that maximizes contrast to the eye, which customarily requires some experimentation by trial and error.
Most mapping procedures require a collection of values regularly
spaced at short intervals, which is rarely the case of training
sets. In addition, interpolation presumes that the variable is
continuous. In those circumstances Harff and Davis (1990)
recommend mapping the group probabilities
by treating them as
regionalized variables and then use the allocation rule to
produce the discontinuous group map. Remember that
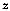 is a shorthand for
is a shorthand for
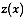 , where
, where
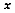 is the location of the site.
Then the probabilities are actually regionalized variables
is the location of the site.
Then the probabilities are actually regionalized variables
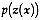 or
or
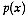 that depend on location.
One does group allocation node by node performing a grid-to-grid
operation in which one assigns each node to the group with the
highest probability.
that depend on location.
One does group allocation node by node performing a grid-to-grid
operation in which one assigns each node to the group with the
highest probability.
Considering that each site must be fully sampled to allow for the cluster and discriminant analysis, there is no advantage on using cokriging for the estimations. Although the probabilities sum to a constant, use of alr transformation is not feasible due to the numerous zeros both in the numerator resulting in a null argument for the logarithm, or in the denominator producing unacceptable ratios.
Ordinary or universal kriging, the default geostatistical options of choice, suffer from the inability to restrict the estimates to an intervalŃ0-1 in this instanceŃlet alone to force the probabilities to sum to one. Estimates outside the 0-1 interval, however, are rare and never far away from the interval. A common solution to force a vector in a coregionalization to add to one is to rescale the values. Considering that such correction does not change the ranking of the membership probabilities, the allocation is insensitive to the rescaling.
Alternative strategies involving the interpolation of the coregionalization itself or of the generalized distances instead of the membership probabilities are deceptive choices. Although the probabilities end up honoring all constraints, the use of estimates instead of true values results in unaccounted propagation of errors.
Allocation in regionalized classification remains open to improvements.
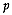 attributes.
attributes.
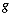 groups either by using Algorithm
1 or any other cluster analysis procedure, or on the basis of
external information
groups either by using Algorithm
1 or any other cluster analysis procedure, or on the basis of
external information